
How we spend our Engineering budgets
I’ve been thinking a lot about how many people, how many tasks, how much effort, how much cost for public cloud managed services you should be allocating as an engineering leader.
There’s this promise that with each layer of increasing abstraction in modern software development we’ll be freeing up ‘developers’ to do more customer value work. It’s hard to argue with the impulse, and the logic makes a lot of sense. But in practice as I think about the evolution of software applications we’ve seen this promise before. I do think each successive wave of innovation is increasingly orienting ‘builders’ towards users, but each layer of abstraction comes with it’s own opportunities and costs.
If I think about how software development practices/architectures have enabled our ability to invest a larger share of our efforts I can propose a split between user value effort vs utility work
how much time & money we spend building the part the user needs for value) versus utility work
vs
how much effort we spend on everything from networking, security, dev tools, test & monitoring, abstract data management code, memory or disk management, etc
Here’s how I think many of us imagine it, or want it to be. We’re driving towards a future where the majority of your efforts are directly related to user experience, improving recommendations, increasing conversions, increasing retention and engagement, and treating all that back-end stuff as commodity.
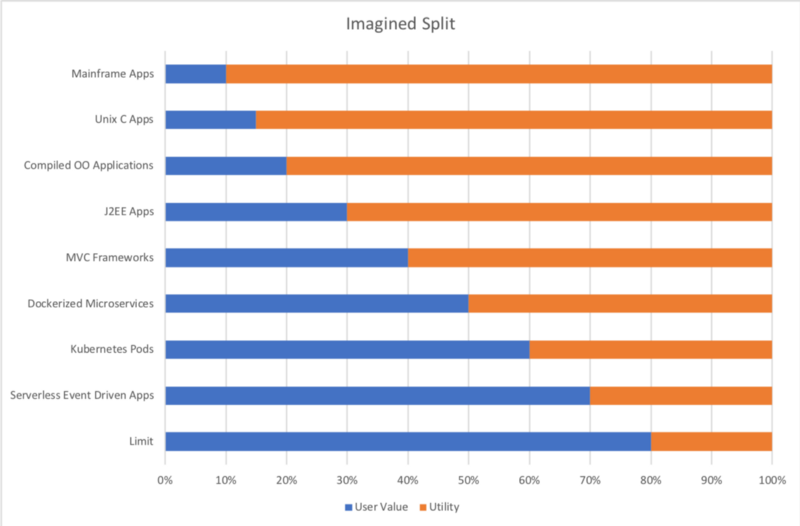
But if I try to allocate a budget (starting back in the 70s) of an organization at scale, I end up with a very different set of numbers.
34% User Value seems to be some sort of limit, and that may even be naive and optimistic. I’m certain I’ve left out major categories of effort in this list, and it doesn’t even begin to include investment in product designers/managers, project management, or any of the usually distinct and separate departments like marketing and human resources. The problem might simply be one of allocation ambiguity. What is direct effort towards customer value? Data Science and Data Engineering are projected to become the number one job disciplines within the next decade — so shouldn’t I allocated machine learning in the Customer Value bucket? — not to mention there’s a lot of wiggle room in the term ‘development’. The Serverless category represents my best guess of where I think a large organization at scale should be spending it’s ‘effort budget’ if it has the benefits of event driven distributed architectures managed on a hosted pubic cloud.
These aren’t staffing ratio recommendations (salaries vary wildly) or even story point allocations just ‘effort’ in general.
If instead of User Value/ Utility Effort, we try to think of it in terms of User Value versus Hidden Value, and I sum up my effort budgets from above we end up with a much more realistic picture of the shift towards User Value as software architectures and process have evolved since the 70s.
I also tried to think about what I expect from my cloud/vendor costs (your deployed costs) to run all this ‘allocated effort’. I had to add an additional category because just shipping bits around and store backups and other non-operational data is going to generally eat up 2-10% of your total spend as you reach scale. Here is how I came down on what I’d expect from a large organization at scale operating strategically with an event driven micro-services dominant architecture.
Obviously every business is different, and however you bucket your costs you might have a very different take on these allocations, but I’ve been asked so I thought I’d take the time to put it out there. And for back of the enveloper calculations about Monitoring, I’ve consolidated several sub-categories into a single Infra category — nota bene — I’ve lumped cloud costs, vendor costs, APM, auditable transaction logs, and operational infra monitoring under the single category of Monitoring.
So finally, in answer this question
It looks like my back of the enveloper calculation is 6 to 1 ratio for infra versus observing infra spend.